It has been asked numerous times, both from inside and outside the project (it got asked so much in Slack that I finally had to append to one of our channel topics a statement informing readers that we are not, in fact, rebuilding the client), why Eleven is using Flash instead of HTML5 to build the game client. We appreciate the concern, and as a matter of fact, have discussed the topic fairly extensively. I myself have tried to answer the question many times, in many places, but have never really taken the time to provide a comprehensive rationale for our continued use of Flash.
I suppose the first misconception I’ve seen floating around is that using Flash allows a quicker path to launch, but absolutely no other benefits. From my perspective, the opposite is true. By sticking with Flash for the game client, we actually gain numerous advantages. I’ll address the most obvious (speed of development) first, followed by the two most common concerns people see with Flash (performance and mobile), then discuss the technical hurdles we would face implementing a game client in HTML5, and finally discuss what matters most to me personally: providing an experience on par with that offered by Glitch.
The most obvious advantage gained from continuing to use the Flash client is speed of development. The very first milestone our team accomplished (way back in November, but time has flown and it feels like we’ve progressed so far since what seems like a rather short time ago) was the successful compilation of the Glitch client as provided to us by Tiny Speck. For those who are curious, the process is something like this. My method differed slightly, but the essence is the same. It’s not necessarily a complicated thing to build, but the fact that building the complete client was still a process that took hours to figure out meant that we were dealing with quite the complex beast. It’s about half a million lines of code, and rewriting it would take a significant investment of time. We’re by no means in a rush, but people would like us to open in a (reasonably) timely manner, and we’re trying not to waste your time (as I’ll continue to explain in a bit); HTML5 offers no practical benefit, but numerous downsides, anyway. 🙂
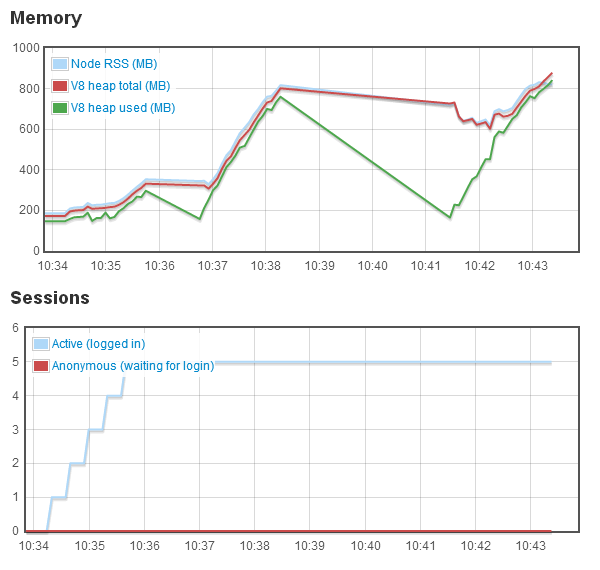
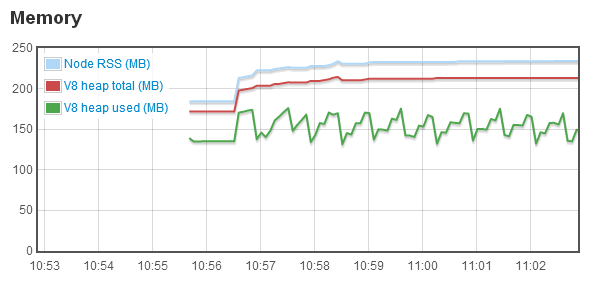
Next up are performance concerns: What are the performance implications of Flash versus HTML5? Not being much of an optimization guru myself, a cursory look at the Glitch client, which still feels like it should run better on the rMBP I bought a couple of months back, would lead one to believe there’s much room for improvement. And maybe there is. However, that improvement would most likely be found by tweaking the Flash client, as opposed to switching to HTML5, which is hardly the performance savior it’s been depicted as. A quote from Cal (Bees!) of Tiny Speck:
“flash is a bit of a performance hog” – try running the same graphics in html5 and you’ll find that flash has very very good performance. unless you’re going to rewrite the client in unity/native-code then flash is going to give you *much* better performance than html5
While I’m in full-on TS-quoting mode, I should also mention the pathway Jono has mentioned for optimizing the Flash client:
“the memory leaks are in the game client, it needs a lot more object pooling”
“the game needs 3/4 GB minimum”
“We cache assets in memory indefinitely too”
Suffice it to say, the Flash client could use some work, but in general, the client works, and in the grand scheme of things, works well, so it’s not on the list of things that’s holding us back from launch, at least in my perspective.
Next up is the relationship between Eleven and mobile devices. In short, such a relationship would mean certain disaster. MMO’s generally are not something you want to implement on a mobile device. Once again in the words of Cal (and taking another opportunity to shamelessly plug Slack – its search functionality has made finding all these quotes a piece of cake):
you can compile some flash to ios/android, but:
1) adobe have given up on that
2) it was built for very simple stuff anyway
3) glitch requires high bandwidth / low latency that you generally don’t get on phones
4) it’s very cpu/gpu intensive with lots of very large textures
5) mmos aren’t really possible under ios app store guidelines – the content & behavior needs to be built into the app
6) typing & playing on a tablet is pretty terrible
glitch is not a game that was designed for or could work (as-is) on mobile
In short, an MMO, especially a social MMO like Glitch, is not something you’d want to play on a mobile device. The experience would be awful, and it would also discourage the social behavior we’d like to encourage. Speaking from personal experience, I frequently remoted into my web server from my phone to chat with people in Glitch, and it was almost impossible to hold a fluent conversation. We seek to offer a pleasant experience, and supporting mobile devices would degrade that heavily.
The penultimate reason for our decision to stick with Flash (and the part of this post that [finally] includes the cool screenshot you’ve probably been waiting for, and may well have skipped through the rest of the article to find) is that the Glitch client is a technical marvel, that would be next to impossible to replicate. But, you say, shortly after The End of the World, there were various HTML5 remakes of small parts of the game! True. But some of the more difficult parts to re-implement are the ones you don’t see. Namely, LocoDeco, the Eleven/Glitch level editor.
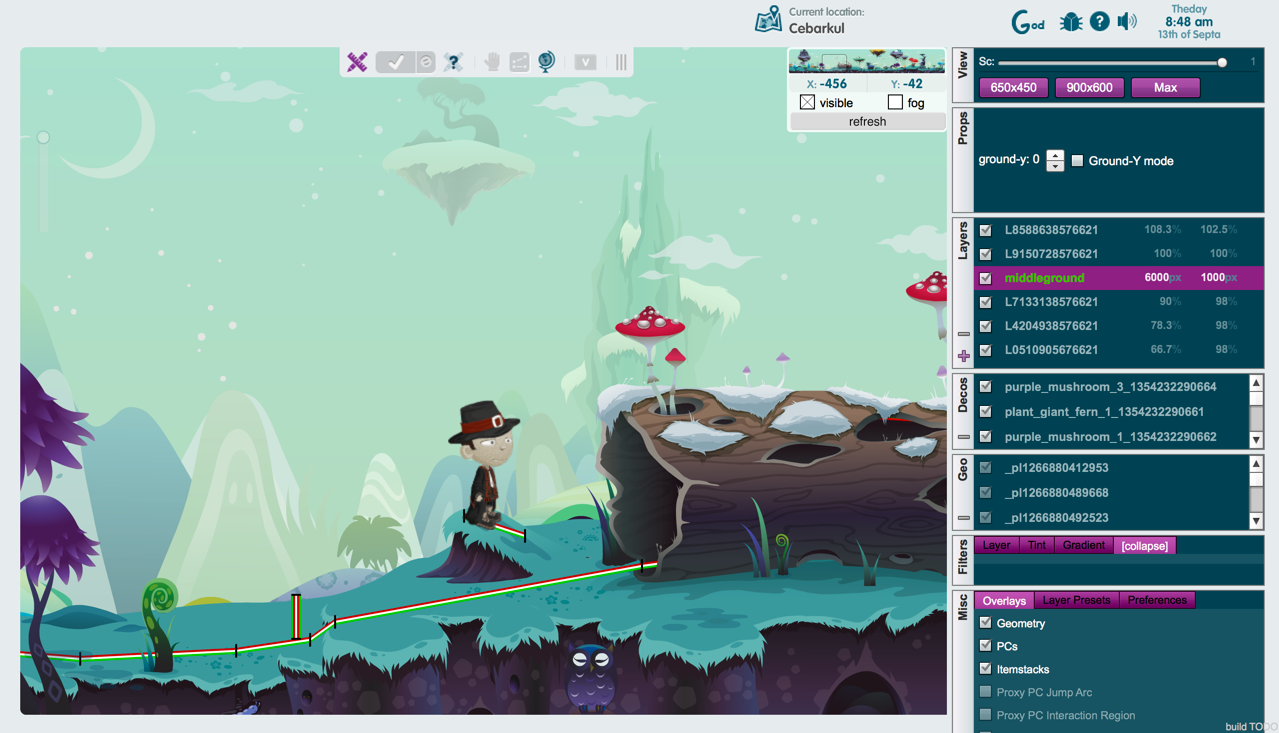
As you can see, it’s a fairly complex tool, and possibly one of the more advanced things ever done with Flash (I’m not the only member of our team to have made this observation). Its use is reminiscent of Photoshop in a way (and having used Photoshop most certainly helps one figure it out). Even if HTML5 were more mature as a technology, I highly doubt something like this would be possible to implement in it (as it is, it’s a testament to the coding prowess of Tiny Speck that they managed to create such an advanced design tool in a platform originally designed to play simple animations on web pages).
Finally, there’s the reason for sticking with the Flash client that matters the most to me personally. It’s why I’m so passionate about this particular issue. In order to deliver an experience that “feels” like Glitch, we need to use the Flash client. Even if it came at some cost in other areas, that’s priceless. We need things like the physics engine baked into the client to work exactly as they were, or things just won’t feel right. If we thought we could’ve done this without the myriad resources Tiny Speck released into the public domain, we could’ve started much earlier (and yet, we probably wouldn’t be nearly as far along as we are now – building an MMO from scratch is nigh-impossible). And using the client TS so graciously provided to us, that can happen. I think Kukubee put it best a couple of weeks ago when we demonstrated our progress to a few of the folks at Tiny Speck:
Kukubee: “damn motherfather, this is glitch!”
And that’s exactly what we’re going for. Nothing less. We’ve discussed it time and again, but if we wish to provide a quality experience, it’s the only way to go forward. I suppose that ultimately, I don’t get the affinity toward HTML5. Presumably what everyone really wants is the Glitch experience they know and love, and we’re trying to deliver that in the best way possible.
Like this:
Like Loading...